

A CENTRAL thesis of global warming is that temperatures will keep going up, and up. They did from about 1960 to 2002 at many places around Australia, but not at all of them. At Ruthergen, a wine-growing region of north-eastern Victoria, temperatures have been fairly steady since a Stevenson screen was erected and temperatures first recorded back in November 1912. 
The Bureau of Meteorology includes Rutherglen in a network of stations that it uses to report on regional and national temperatures. But it doesn’t report on the temperature values as recorded at Rutherglen. It first remodels them. Through this process the mean annual minium temperature trend is changed from cooling of 0.35 degree celsius per century to warming of 1.73 degree celsius per century. That’s a pretty large change in both magnitude and direction.
Since this was first reported in The Australian by Graham Lloyd there have been accusations that people like myself are into conspiracy theories, and more. But we really would just like some answers.
No one is more curious than Bill Johnston. He is disappointed that Andy Pitman and other Australian climate experts seem to be avoiding discussion of the temperature data for Rutherglen. Out of curiosity, and also in an attempt to generate some scientific interest amongst his collegues, Dr Johnston has undertaken the following analysis. It’s a bit technical. But hopefully not too technical for the experts.
Rutherglen – A brief overview by Bill Johnston
I examined the data graphically using a CuSum curve (cumulated deviations from the grand mean). There were 4 turning points, in 1923, 1957, 1964 and 1975. Two of those could have been independently-documented climate shifts (~1923 and ~1975).
I analysed the annual minimum temperature data, down-loaded from BoM using shift-detection software (CPA from variation.com) and sequential t-tests (STARS) (see: http://www.beringclimate.noaa.gov/regimes/rodionov_var.pdf) allowing for autocorrelation; and assuming all data were in-range (Huber’s H = 5).
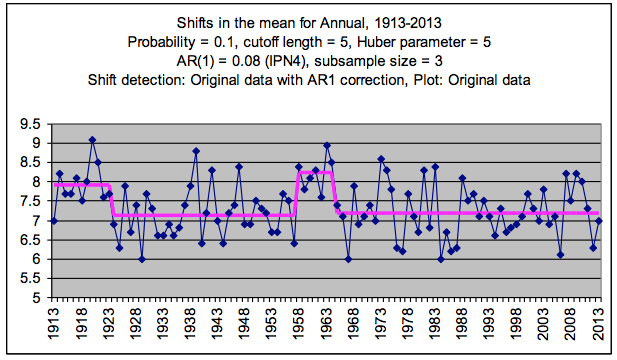
CPA, which is based on bootstrapping, is not so good, when there are numerous changepoints. However, it detected shifts in 1924 and 1937 (P = 99% and 82% respectively). I did not follow-through fine-tuning the methodology, as I’d normally do to ensure no additional steps.
STARS detected regime changes in 1924 (P = 0.0007), 1958 (P = 6.07E-06) and 1965 P = 3.85E-06). This was inconsistent with the published metadata. The ACORN catalogue mentions no station moves. The steps were not documented climate-change years.
STARS settings are indicated on the graphic, so anyone can obtain the STARS Excel add-in, and data and re-do the analysis and check my interpretation. (Years indicated are start-years for the new regime.)
Of the step-changes, the 1965 shift was the most influential. Ignoring the intervening ‘hump’ the difference in mean level between 1957 and 1965 was 0.06 degree C.
Because it occurs in the middle of the dataset, such a step change could be trend-determining. If the hump alone was deducted, by shifting the data down by the difference, the 1965 shift may not be detectable. Trend however, would be little altered, and would still be no different to zero-trend.
The hump could have been a data-fill; a temporary move or a change in screen-aspect or instruments; but that is all a guess.
The shift down in 1924 of 0.77 degree C is consistent with a possible station move. However, based on Metadata, no such move happened, which was the point made by Jennifer Marohasy, which in-turn was based on the best information available from the BoM ACORN catalogue.
If we go back to BoM’s climate data on line, there was a post office record (082038; 1903-1925) as well as a viticulture research record (082085; 1903-1927). I’ve not compared these, but at an annual scale, they should behave in parallel (same trend, different intercepts).
(A graphical way of checking is to difference the datasets, and cumulatively sum the result, to see if the CuSum of the difference goes ‘off-line”. (Add a to b, then the answer, to c and so on – it takes 2 calculation columns, one for the difference, the other for the CuSum, and data needs to be closed-up on missing pairs). I think visual comparisons; using line-graphs are difficult to interpret. (Also some people have trouble with discerning colours.) Comparing regression lines may also introduce the possibility of spurious trends in either or both of the datasets being compared.
It so happens that in my research collaboration days, our team met time-about in the historic and interesting viticulture laboratory, which became a meeting room within the Rutherglen Research complex.
It seems likely that, in order to produce the long ACORN record; between 1924 and 1927, the viticulture record was merged with the Rutherglen Research record, and that BoM ignored or did not detect that particular stitch.
It could also have been an inadvertent error; the sort of thing that happens when someplace morphs into something else. (It could have been done locally for example.) (I don’t know when Rutherglen became an agricultural research centre.)
Irrespective of all the argy-bargy, the important points are:
1. The truth is in the data, not necessarily the metadata.
2. Without leaving Excel, small (less than 1 degree C) enduring shifts in the mean level of a data-stream, typical of undocumented changes, can be detected. However, for any time-series iterative testing using contrasting tests, and interpretive skill is required (at the 95% level there is a 5% chance of NOT detecting a shift that is real).
3. Most importantly, in the case of Rutherglen (and Deniliquin; RAAF Amberley; Longreach; Nobbys Head, Moruya PS and elsewhere) when abrupt-shifts are allowed for (deducted sign-intact), it is often the case residual trends are not different to zero-trend. (It can also be the case that the data are useless; Eucla may be in that category!)
In other words, for many places, naïve mean-squares trends may be spurious. They are due to shifts either in the measurements or in the climate.
In Rutherglen’s case, trend between 1924 and 1957 (34 years), and between 1958 and 2013 (49 years) were no different to (bootstrapped) zero trend (P <0.05). (Least squares trends were 0.007 and –0.003 oC/yr.) This further supports the view that we have a non-trending data stream, containing a small step. According to CPA and STARS there were no significant (P <0.05) changes in variability. With all step-changes removed, there was no trend. There are four important lessons. 1. Graphical and statistical evaluation on a site-by-site basis is essential before any inter-station comparisons, or inter-station homogenizations are undertaken. This is formally called exploratory data analysis (EDA). My endless analysis of data leads me to conclude that many series are not fit-for-purpose; or that it is simply not possible to detect valid trends against background noise. (Valid trends are trends ex-steps. For least-squares regression to be valid, data MUST be homogeneous.) 2. There can be changes within data that are undocumented (like Rutherglen and Amberley); likewise there can be documented changes that don’t result in data inhomogeneties (Eucla possibly being a case in point). 3. It is inappropriate for the Bureau having made a mistake in respect of supporting comments made by Professor David Karoly, who has a long history of being biased; to pull in heavy artillery from another, potentially equally-biased UNSW group, in an attempt to reclaim the high-ground. 4. There is an answer. I’ve put forward a transparent approach. Having said that I’m quite willing to be proved wrong at the statistical confidence level of P =0.05. The situation has become a bit absurd.
The Bureau needs to show unambiguously ‘true’ or ‘real’ uncontestable positive trends in minimum temperature data that don’t rely on their homogenisation procedures.
It is really that simple.
If BoM cannot do that, they have lost the statistical debate and need to fess-up or develop yet another trend-setting dataset.
Cheers,
Dr Bill Johnston
Former NSW Natural Resources Research Scientist
Note that I am a data analyst, not an expert mathematical statistician. I would not be regarded as an expert in the sense of arguing a statistical case with BoM, for example. That does not invalidate my analysis; it is simply a disclaimer. And if you want disclaimers, look no further than most BoM reports.
 Jennifer Marohasy BSc PhD is a critical thinker with expertise in the scientific method.
Jennifer Marohasy BSc PhD is a critical thinker with expertise in the scientific method.

Jennifer have you noticed this post by Mikky at Jo Nova’s latest thread? It’s a study by Gergis and Karoly looking at temp, rainfall ,enso, iod etc from 1860 to 2009 for SE Australia.
They claim that they may be able to go back to 1840. Of course they missed out on the big rainfall events after 2009 and the rainfall trend is now slightly positive for SE OZ. But here are Mikky’s two posts.
Mikky
September 3, 2014 at 6:39 pm · Reply
This recent study of South East Australian temp and rainfall history from 1860 suggests that everything is consistent with variations in ENSO and IOD (Indian Ocean Dipole), no mention of the dreaded CO2.
What a shame that some climate scientists look no further than the currently fashionable theory of the CO2 thermostat.
http://onlinelibrary.wiley.com/doi/10.1002/joc.3812/abstract (Southeastern Australian climate variability 1860–2009: a multivariate analysis, Linden Ashcroft*, David John Karoly and Joëlle Gergis)
Abstract
Historical datasets of instrumental temperature, rainfall and atmospheric pressure observations have recently been developed for southeastern Australia (SEA), extending the regional climate record back to 1860. In this study we use the newly extended datasets to conduct the first multivariate examination of SEA climatic changes from 1860 to 2009.
The climate in SEA is highly variable in response to fluctuations in large-scale circulation features including El Niño–Southern Oscillation (ENSO) and the Indian Ocean Dipole (IOD). To examine how teleconnection patterns in the SEA region have changed over time, we then applied a path analysis over the 1871–2009 period to isolate the independent relationships between SEA climate variables, ENSO and the IOD. The extended data revealed several relatively unknown periods of 19th century SEA climate variations. Cool and wet conditions were identified in the early parts of the 1860s, 1870s and 1890s, while dry conditions were found in the late 1870s, 1880–1885, and during the well-known Federation Drought (1895–1902).
Path analysis identified a decrease in the influence of ENSO on SEA rainfall during 1920–1959, particularly in the austral winter. Increasing correlations between the IOD and annual SEA rainfall and pressure were found in the recent 1970–2009 period, but appear to be within the range of natural variability in the context of the last 140 years. Despite large changes in the correlations between SEA rainfall, ENSO and the IOD, correlations between SEA rainfall and temperature remained stable over 1871–2009. Similar results were obtained using 20th Century Reanalysis data for 1871–2009, supporting the quality of the extended historical datasets and providing verification for the reanalysis data in SEA from the late 19th century.
Report this
30
#11.1
Mikky
September 3, 2014 at 6:51 pm · Reply
Related material from linden Ashcroft:
http://www.wcrp-climate.org/conference2011/posters/C23/C23_Ashcroft_T180A.pdf
A poster presentation, including an annotated example of temp homogenisation.
See also the poster pdf available here: http://www.researchgate.net/publication/258771102_Southeastern_Australia_climate_variations_1860-2009_using_historical_data_to_test_teleconnection_stability
Thanks Neville, I’m aware of the paper. Karoly and others have actually use ENSO and other climate indices to justify homogenisation. But can any discussion of this please be at the “Open Thread”.
I would like this thread to be about Rutherglen and in particular Bill’s analysis. All other comments should be posted at the “Open Thread”.
Many thanks to Bill for providing this analysis, it looks like he is confirming (indirectly) that there were no instrumental changes at Rutherglen in 1974.
That to me is the key point, that there is compelling evidence that the BoMs automatic change-detector has false detections. I believe that is a general feature of such detectors, but BoM will be encouraged (forced?) to do some checking and revision by the proof provided by Bill that it is required in at least one location.
Maybe BoM should write to and seek confirmation from all ex-employees at sites where there has been automatic change detection without metadata support.
Always thought the site at RRS was the definition of heat island effect. Buildings, concrete paths, metal cage around it.
Wouldn’t it be funny if the site shifting detection was actually detecting some major physical change at the site.?
In winemaking we know that concept as terroir, and it explains why you can have great wine being made next door to vin very ordinare. Not just soils , trellising system, and climate, but the effects of trees, buildings, rivers, everything that effects the microclimate of the vine..the climate inside the vine canopy on the grapes.
Wow…and we use homogenization from Hillston.
Rutherglen is fed by 2 major weather systems, the General weather pattern from the west, and the tropical weather patterns from the north. Rutherglen is roughly at the southern extremity of the Northern summer rains which tend to split and go up the valleys into the hills. check out the rainfall data…we get massive variation over very short distances.
What happens when the ” change comes through”.? It cools off.
you get some summer storms and miss others.
It’s why Rutherglen could grow vines without supplementary irrigation on 550 mm…and some years..way less.
Homogenisation is scientifically inappropriate for looking at a weather station data in a river valley like Rutherglen..only a short distance from the Great Dividing Range. ( it’s the foothills)
My house gets 500 mm annually based on my neighbors long term data..they have been there for 100 years. across the river some 10 km away…375-400 mm.
With the difference being those summer storms.
The RRS site is well away from buildings in a slight hollow in the landscape.
The points I’m making are really the 4 lessons at the end.
The one to stress is EDA – otherwise known as know thy data.
A computer operating without a human brain attached is not much use; which can be a problem for auto-homogenisation.
The rainfall effect is important. Rainfall is a well-documented temperature co-variable, although its effect may be different for Max vs. Min temps. At some sites it can explain upwards of 20% of temperature variation. So a comparison of disparate stations, such as Rutherglen and Wagga Wagga; or Hillston, may reflect rainfall differences, which might be substantial at those distances. I could be wrong, but I don’t think homogenisation takes care of that.
I’ve been involved in low-level climate work for decades. As well I’ve been an observer at a standard met-lawn for many years.
There are many possibilities for bias and error, especially before a consistent effort was made in the 1970’s to standardise practices.
I’m not saying that observers were slack, its just that historically, well-before the CO2 clamor, they had no idea that 50 to 100 years after their observations were written down; 1 or 2 generations later in some cases, our BoM would be going over their figures trying to prove something the data were not collected to prove.
Polishing data up; implying precision that does not exist in the original observations; such as records broken by a single decimal-place, without providing an uncertainty measure is simply not scientific. I’m sure they have some brilliant, unbiased and hard-working people who know this. Which gets me right to the important Rule #1 “know thy data”.
Lucky they write good-disclaimers in their glossy-docs!
Well done Bill. I am part way through doing the discontinuity detection by pair-wise differences from neighbours that the BOM claim to have used. There are 153 comparisons to be made! So far, I suspect (but can’t yet confirm) a small (0.5) shift up in 1958, and a smaller shift down in about . I don’t see a step change in 1965 or 1966, or 1924, but a small step down about 1929 and up again about 1937 , but there are sharp one year spikes down in 1925 and 1954, and an indisputable one down in 1967. I would need to complete the testing but will comment further, maybe post, when finished. What I really suspect is that BOM did NOT do what they said.
Thursday, and they have wheeled out Nev Nicholls:
https://theconversation.com/how-to-become-a-citizen-climate-sleuth-31100
Nicholls reminds us of his 25 years of studies.
it was ok to quote early weather records when it suits him:
“Governor Arthur Phillip wrote the following to the Colonial Secretary, the Right Honourable W. W. Grenville on 4 March 1791:
“From June until the present time so little rain has fallen that most of the runs of water in the different parts of the harbour have been dried up for several months, and the run which supplies this settlement is greatly reduced, but still sufficient for all culinary purposes… I do not think it probable that so dry a season often occurs. Our crops of corn have suffered greatly from the dry weather.”
http://www.abc.net.au/science/slab/elnino/story.htm
And this quote:
“We have to start with the sun.
The driving force of the climate is energy received from the sun.”
“WHAT ABOUT THE GREENHOUSE EFFECT?
The next challenge may be to understand and predict how the El Niño – Southern Oscillation will react to climate change, especially any change humans may cause.”
So how is that going, Nev?
25 years later …
March 7, 2014
El Nino may arrive as early as mid year, US climate centre says
http://www.brisbanetimes.com.au/environment/weather/el-nino-may-arrive-as-early-as-mid-year-us-climate-centre-says-20140307-34ass.html
BoM, MAY 08, 2014
El Niño has been forecast to return in 2014 and it could be a big one
http://www.dailytelegraph.com.au/technology/el-nio-has-been-forecast-to-return-in-2014-and-it-could-be-a-big-one/story-fnjww4q8-1226910244082
02 September 2014
Stalled El Niño poised to resurge
“If we don’t see an El Niño this year, then we have a big black mark on the model performance,” says Barnston.
http://www.nature.com/news/stalled-el-niño-poised-to-resurge-1.15814
Yah thinks so?
Graham Lloyd has a piece in today’s The Australian about Rutherglen and the temperature record, explaining that:
“The BOM has been unable to supply physical records to confirm the thermometer site at Rutherglen has moved to help explain a change in temperature trend from cooling to warming.”
Apparently a peer review panel has even said this information should be available.
http://www.theaustralian.com.au/news/nation/more-time-to-find-rutherglen-temperature-record/story-e6frg6nf-1227046989433
But, as I see it, the information will never be forthcoming because the site has never moved. Time to accept that our BOM has a current management that just makes it up as they go along. Shame on them. But surely, as Bill Johnston has suggested to me, its time for Andy Pitman and others to make a stand for the integrity of the record, for the integrity of climate science.
I wonder whether repainting of the Stevenson screen has had an influence – between whitewash and oil paint and plastic paint and also paint deterioration over time.
A similar analysis of maximum and minimum temperatures may provide the answer, with the repainting showing up as steps in the maximum not showing in the minimum.
Just another quote from the Nev Nicholls piece from 1997:
“In BMRC, we have documented changes in the impact of the phenomenon on Australia, with recent El Niño events apparently not resulting in droughts quite as severe as in the past.
It appears that the recent more frequent El Niño events have been offset to some extent by them being a bit less dry.”
http://www.abc.net.au/science/slab/elnino/story.htm
2013 hottest year ever?
Man Made?
Gaia only knows what Pitman, Nicholls et al are thinking.
To Graham Lloyd; BoM could simply be searching for a large magic carpet-square to sweep this under. The answer to the dilemma is simple.
The most important underlying assumption for determining a valid trend, is that data need to be homogeneous; that is the series contains no steps and bumps due potentially to extraneous ‘factors’ such as station moves; and importantly, gross shifts in the climate; likened by way of example only, to the climate of Wollongong abruptly shifting north to Sydney.
As I’ve demonstrated, these two possibilities can be tested from within a series. In addition, major climate shifts have been independently reasonably well documented. So if they are found, these can be ticked-off..
In Australia, there are in-fact very few long-term continuous data sets. BoM used to have a list available on their website, but it’s been withdrawn. There is also no concise list of how many, which and when sites were automated, which potentially is another issue affecting trends and ‘records’.
To David Karoly: I’ve shown you mine; now you show me yours.
For the last 10-years you have hounded the community relentlessly about climate warming and change. Change has always happened within our climate systems; our river systems and along our coastlines. Warming stopped ~20 years ago. So why don’t you stop?
To Andy Pitman; my essay is not actually about Rutherglen. I could have written about any number of temperature and rainfall recording stations, or sea-level datasets. It is also not about magic mathematical carpets, or long words that normal people can’t understand. It is really about “know thy data”, and when you look closely, most data are pretty ordinary for determining trend. Feel-free, Andy, to repeat my analysis. At least address the issue at hand.
Bill. I don’t think RHtestsV4 (as you pointed to previously) is the ACORN-SAT software. It’s a different implementation for North America I think, Quartile Matching, not Percentile Matching for a start. It’s probably a similar example but I can find no reference to RHtestsV4 at BOM or TR049 or searching ACORN-SAT RHtestsV4 on the web.
The manual you linked to was this:
http://etccdi.pacificclimate.org/RHtest/RHtestsV4_UserManual_20July2013.pdf
Could you please confirm, or otherwise, that RHtestsV4 is actually the ACORN-SAT software as used by BOM with some reference, link, or quote?
That’s it.
I’m cooking popcorn.
Ms. JM is commenting @the con.
There will be a lot of deleted comments is my prediction!
[Bill] >”A computer operating without a human brain attached is not much use; which can be a problem for auto-homogenisation.”
Yes, exactly. And auto-adjustments (i.e. there’s 2 methods: homogenization M&W09, and adjustment PM95). This statement is what Mikky and myself have been getting at over the last few days. Mikky thought, I infer, that a lack of “human intervention” is at the bottom of this. So do I.
Methods and automation of them – fine. But assuming that a single adjustment, especially a large one that turns a cooling trend into a warming trend, must be made simply because the software detected a discontinuity is not fine even if the warming trend is a “regional expectation” (as BEST circular reasoning puts it). The rules built into the software cannot make an assessment of the adjustment validity, but humans can from other information like the site history. If no non-climatic reason for the discontinuity can be humanly found then the auto-adjustment for it is immediately suspect requiring human scrutiny, and maybe weather is climate afterall.
>’STARS detected regime changes in 1924 (P = 0.0007), 1958 (P = 6.07E-06) and 1965 P = 3.85E-06).”
But not 1980?
BEST make a substantial adjustment for a “Record Gap” (turns cooling into warming) at 1980 by their “scalpel” method” (and a truncated dataset note):
http://berkeleyearth.lbl.gov/stations/151882
Note: I had previously thought this corresponded to a step change in ACORN Max but I was confusing Amberley Max where there is a very large step at 1980.
I self-corrected at JN ‘Explain this’ #17.2 too, asking”
Begs the question: why does BEST make such a large “Record Gap” adj for 1980 (turning cooling into warming) but BOM doesn’t?
Richard,
The paper by Ashcroft, Karoly and Gergis (2012) “Temperature variations of southeastern Australia, 1860–2011” Australian Meteorological and Oceanographic Journal 62:227-245 used RHtestv3 as their homogenisation tool, which led me to believe the principles behind it were in general use by BoM. (v3 been updated to v4) Happy to be wrong; and I’m not pretending to be an expert, but somewhere deep within the ACORN docs. is reference to percentile matching. Also bear in mind that percentiles are quantiles and vice versa. Best to ask BoM to confirm perhaps?
Steps in Amberley min were 1972 and 1980. I have not paid much notice to max lately; I’d just like to settle the min issue first; and Rutherglen min in particular, because ACORN metadata, which is crucial to understanding the actual data, said there were no station moves. It seems bizarre to me that BoM have to find money and resources to look into their own data!
Cheers,
Bill
BJ said
“Graphical and statistical evaluation on a site-by-site basis is essential before any inter-station comparisons”
Finally I find someone who has the same approach to data analysis.
I analyse data, form about 150 different locations (not climate) and would not think of homogenising them although it would make programming down the line a lot easier.
Also the way to treat anomalies is not to discard them out of hand but at least put them aside and investigate the reason for it later. If turns out to be bad data, then sure discard it then.
As I said before, a particularly hot or cold day or spell, unusual for the season would be mentioned in local records other than the temperature record itself.
I would’ve thought that’s what proper science was all about, investigate and research before coming to conclusions.
Johnathon, you made the mistake of believing that climate scientists are involved in proper science. Most are people who naively believe what someone else did is properly researched science, then use it themselves to further their government/academic career to support their lifestyle. And the bloke they are copying is a political activist with a degree.
Jen and Bill, I can’t believe how the group thinkers at the Con duck, weave and obfuscate rather than do not only what the both of you suggest but also the article itself, i.e. check for themselves.
Instead they howl “peer review!, peer review!” hoping that will hide the truth indefinitely.
Looking forward to your SL report too, Bill.
Well done Bill!
I think what you’ve shown me is:
[1] It’s very feasible for a “citizen scientist” to get hold of most of the raw BOM data and perform their own tests on them. That is great news for openness, and gives more power to the people. Even more so when you can use climate scientist Rodionov’s statistical techniques for regime shifts. See – these guys aren’t so bad after all!
[2] It’s very clear that you realize “raw” data is something to work with, and possibly manipulate, before it accords more closely with any sense of physical reality. That’s an important lesson that any experimental physical scientist needs to get across. At its simplest level it’s about constant re-calibration (and that is not always trivial). As you will be aware, the measurement of temperature outdoors is deliciously susceptible to systematic error when you’re trying to run these sort of time-series. In no sense is the “raw data” anything other than something that should be kept sacrosanct and safe as the starting point for working out what is “really” happening.
[2] If I was you, I would be tempted to run your sequential t-tests on monthly variations from the mean. I think there’s a body of literature showing that analyzing variations tends to be more sensitive. I would also work on the max temperatures, too. If you write the correct sort of macros in Excel, it should all start being less time consuming.
[3] I think you then need to analyse Rutherglen relative to neighbouring stations, if you want to start getting an idea of what BOM have been up to. Given the magnitude of the shifts you can probably spot the issues by plotting them together and seeing why Rutherglen appears to deviate from the trends of the other stations. If you wish to be more sophisticated then there’s a host of correlation techniques available – but I’m not sure what you might get in Excel, as it’s fairly limited, and I’ve never used it for statistical analysis. However, I did find this website:
http://www.real-statistics.com/
that should help in finding some useful techniques within Excel.
[4] Once you have done all this – I suspect you’ll find when and why BOM have made the corrections they have, although obviously your numbers will be a little different and you may not get absolutely the full picture. After all, complex statistical analysis isn’t there simply to befuddle the uninitiated, but it’s been shown to work on real data sets! (I’m not commenting on homogenization techniques, as I know less about them than I know about my daughter’s day at school….)
The beauty of all of this is that you can work out what they’ve done, and if you have a better and more robust technique to improve upon it, you can move forward. Or you may have a meteorological view on why the stations used for correlation are inappropriate. And then you can blog about it, write to The Australian about it, or write a paper about it – doesn’t need to be for peer-review, whatever you wish.
However, I think it would be unreasonable to expect BOM to jump every time you, or Jennifer, or The Australian get hot under the collar. And it would certainly be unreasonable to expect fast responses within a given news cycle.
Good, considered, science is never best performed in a rush or on the pages of newspapers. But you have the data, and if you can demonstrate that BOMs efforts to decrease the systematic errors in their observations is sub-optimal, or (as is claimed in places) simply a means to increase the temperature of Australia, then all power to you.
Good luck,
David
Bill said:
I’m not saying that observers were slack, its just that historically, well-before the CO2 clamor, they had no idea that 50 to 100 years after their observations were written down; 1 or 2 generations later in some cases, our BoM would be going over their figures trying to prove something the data were not collected to prove.
Yes, and given that the claimed rate of warming is 1C or less, and the adjustments are of a similar order of magnitude, then further it is claimed that such a trend supports the climate models which predict catastrophic, CO2-caused warming, we are getting into Alice In Wonderland territory.
“However, I think it would be unreasonable to expect BOM to jump every time you, or Jennifer, or The Australian get hot under the collar.”
Is making substantial criticism or expressing well-founded doubt the same as getting hot under the collar? BoM should respond. If they feel they don’t have to “jump” then they should take a day or two. Then they should respond.
I think Jen and Bill know about their freedoms to blog, correspond and write papers. Guidance on excel and stats is found in seconds on the web, though I don’t doubt that some educational suggestions may be valuable. We can all use some of that!
However Bill and others shouldn’t be diverted from this specific urgent matter of the Rutherglen temps and the justification for what Jen calls “a pretty large change in both magnitude and direction”. That ball has to be kept in play.
And when we speak of change in direction, there is something all together too predictable and familiar about the direction taken: namely, from cooler to hotter. That’s getting to be a sub-optimal look, to put it nicely.
BoM really needs to clear this up. They might think they don’t have to. They do have to.
511KEV:
Point 3: That is precisely what I am currently doing. With 100% of the sites for which the Bureau has released the identities of reference stations i.e. only Rutherglen. Stay tuned.
Has the BoM done the simple check of reversing the years of data for each station to demonstrate their adjustment algorithm at least operates in a symmetrical manner?
Bill, thanks re RHtestv4
>”….which led me to believe the principles behind it were in general use by BoM.”
It would and it’s a start, I suspect that package has been adapted by BoM for their PM variant rather than code from scratch. Just a hunch so will look into this over time. BoM has adapted Menne & Williams (2009) for their initial homogenization (M&W09) so makes sense that they probably haven’t reinvented the wheel for adjustments (PM95) either (but see below).
>”Happy to be wrong;”
Well, at this stage you’re not yet necessarily wrong as above.
>”….somewhere deep within the ACORN docs. is reference to percentile matching.”
Actually it’s very explicit. I’ve laid out the provenance of BoM’s adoption of M&W09 and PM95 at the JoNova post ‘Hiding something’ #38.2 here:
http://joannenova.com.au/2014/08/hiding-something-bom-throws-out-bourkes-hot-historic-data-changes-long-cooling-trend-to-warming/#comment-1554309
TR049, page 65 pdf,
7.6 Evaluation of different adjustment methods
“Based on this evaluation, the PM95 method [7.4] with 10 neighbours was selected for use in most cases. Details of the implementation are given in the following section.”
So having decided on the PM95 method, they (BoM) probably went looking for some pre-written software because it’s a pre-existing method. That looks to me what Ashcroft, Karoly and Gergis have done but adopting QM by default. I would have thought BoM assessed RHtestv4 for their use but I’m not convinced they actually do use it but they may very well have adapted it.
In the following comment at JN (#38.2.1) I’ve provided a definition of Percentile Matching from its use in health policy (it’s a statistical modeling technigue involving “parameter estimates”, with “no guarantee that an estimate will be unique”), and a tutorial from the Casualty Actuarial Society.
>”Steps in Amberley min were 1972 and 1980. I have not paid much notice to max lately;”
OK good to know. I didn’t think there would be a very large step in Max without a corresponding step in Min. Amberley Max was investigated by Marohasy et al:
‘Modelling Australian and global temperatures: what’s wrong? Bourke and Amberley as case studies’
http://jennifermarohasy.com/wp-content/uploads/2011/08/Changing_Temperature_Data.pdf
Detecting shifts.
There is a process involved in detecting step-changes (inhomogeneties).
I start with annual data before looking at monthly anomalies (data with monthly grand-means (GM) deducted.
Missing data needs to be filled. If that is not possible, I close-up the data, so there are no gaps. This may introduce some degree of statistical error; so it must be mentioned that data were closed-up on missing values and leave it to the reader to work out the effect of that. Later, its important to check if missing data corresponds to a step; they could signal for example, a station move or new instrument.
Start off with a linear time-plot; look for possible sudden shifts. If shifts are not evident, they probably won’t exist. Plot a regression line and look at variability – the magnitude of ups and downs should look the same along the series. It is also a guide to see if data runs off-trend.
I generally then plot a CuSum (cumulated deviations from the dataset grand mean (GM)).
(CuSum’s for strongly trending data can be misleading. Y values less than the x-centroid, tend to be less than the GM; those >centroid, more than GM; giving the CuSum a ‘U’ shape about the centroid. If this is observed, detrend the data first; i.e. work with residuals.)
A trend-unaffected CuSum, will have one or 2 sharp “V’-shaped inflections. If it has 3 or 4, suspect the data are randomly-varying about the GM; so there is unlikely to be significant change-points.
(A problem with many series is that the 1947 climate shift occurred ~half-way along datasets starting in 1910. An inhomogeneity about that time, or a bit later, could be real; but it will be ‘V’ shaped, not ‘U’ shaped.)
Note the time (year) of suspected changepoints.
Change point analyzer (CPA)
I then use CPA, set usually to detect changes at 50% CI; but to only tabulate change-points where P>90%. CPA produces a CuSum curve overlaid by detected inflections; also a line-plot, showing calculated shifts; and a table of detected changes. Increasing the rigor by increasing the CI from 50% to 80%, for instance, eliminates nuisance or possibly spurious changes. The tradeoff is between detection and inclusion in the table; and the result must be sensible against expectations.
CPA loses-out if there are more than a few change-points and it does not detect well near the ends of a dataset. I use 10,000 bootstraps with replacement; and CuSum estimates. There are other options. It is important to look at documentation relating to handling autocorrelation.
CPA does not provide digital output; but jpg’s which are a bit klunky. I paste them into Excel.
STARS.
Like CPA, STARS also needs to used iteratively. Input is columns in a single worksheet. I usually do my analysis one variable at a time; but you can do 12 for instance. The risk is you end with many changes, none optimised for any particular variable. Missing data or text within a column will cause a runtime error; so remember, for calculated data, to past as values.
I usually presume all the data are real, so set Huber’s H = 4 or 5. I also assume data are autocorrelated, and use the ‘IPN4’ option; STARS will work out necessary compensations for the t-test.
There are several settings Target probability p sets a detection parameter; l, sets a target regime ‘length’ in whatever the time units are. l is a weighted parameter; the default is 10 time units.
The aim of iterative testing is to detect only changes that are meaningful; while ensuring that we don’t fail to detect changes that may be real at the scale we are interested in. (The Type I vs. Type II error conundrum!)
It is achieved by holding p constant while trailing various settings of l or vice versa.
Short l and low p (say 5-years; and 0.5) will detect many spurious and non-meaningful changes (low significances); whereas 5-years and 0.01 will detect significant, short-term shifts, if they exist.
Increasing l to say, 10 or 50, for annual data will detect decadal-scale shifts (if they exist) and if p is set appropriately. A high p (such as 0.3, and l = 20), may detect shifts with a range of t-test P levels; so it’s best to try a range of p and examine the output.
Shifts in the output should be significant at some level of choosing (P<0.05 for instance); and the residuals should be step-free. Remember we are not step-hunting; we are using the tool to investigate data.
An appreciation of the shape of the data, gained from the CuSum (or CPS’s CuSum and other visual clues); together with STARS is a useful diagnostic combination for detecting inhomogeneties.
It is also useful for conducting a ‘blind’ analysis, independent of metadata.
Cheers,
Bill